Overcoming Data Silos in Enterprise Logistics

The modern enterprise supply chain is arguably the most complex logistical mechanism ever devised by human engineering. Millions of components, raw materials, and finished goods traverse oceans, rail lines, and highways every single day, interacting with shifting weather patterns and volatile geopolitical borders. Yet, despite the sheer physical scale of these operations, the greatest threat to building sustainable and resilient global logistics is not a physical barrier. It is a digital one. Across the globe, enterprise supply chains are being suffocated by massive, impenetrable data silos.
In a typical heavy industry or civil engineering enterprise, the data required to build and move physical infrastructure is hopelessly fragmented. The procurement team operates inside one legacy software ecosystem, meticulously tracking capital expenditures and vendor contracts. The logistics and fleet management teams rely on entirely different routing software to monitor terrestrial and maritime transit times. Meanwhile, the Chief Sustainability Officer is often left trying to stitch together Scope 3 carbon emissions data using isolated spreadsheets and retroactive quarterly reports. The organization ultimately possesses all the data required to make an intelligent, low-carbon decision, but because the data is fundamentally disconnected, the enterprise remains functionally blind.
This fragmentation is the absolute death of true sustainability. You simply cannot optimize a global system if you can only see one isolated fraction of it at a time. When a logistics manager optimizes a shipping route strictly to minimize transit time, they might inadvertently select a path that requires carbon-intensive air freight, completely destroying the company’s ESG compliance for the quarter. Conversely, when procurement selects the absolute cheapest structural steel, they might remain completely unaware that the supplier is located in a high-risk climate disruption zone, exposing the entire downstream project to catastrophic logistical delays. This is the inherent danger of localized optimization. When departments operate in data silos, optimizing for a single variable in isolation almost always guarantees a systemic failure somewhere else in the supply chain.
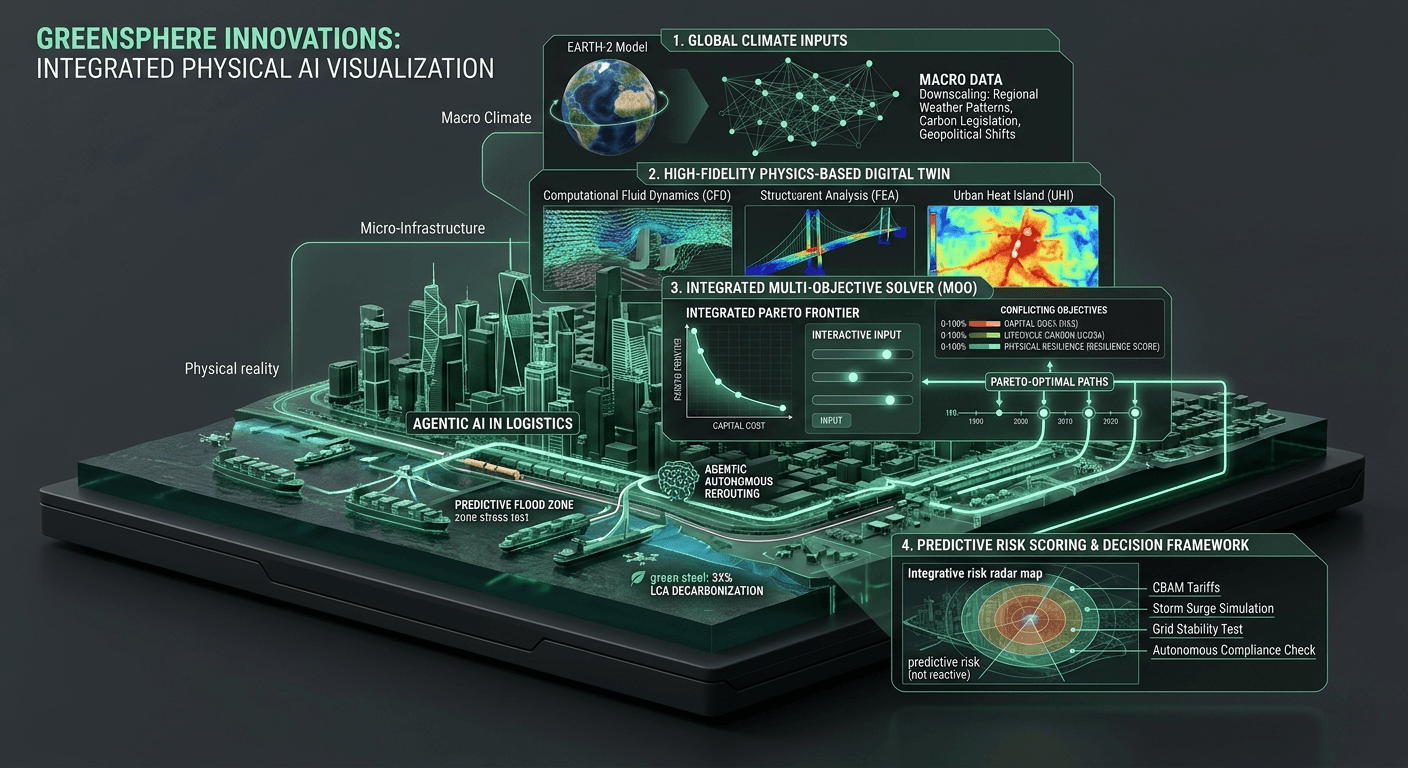
At GreenSphere Innovations, our core architectural thesis is built around Multi-Objective Optimization (MOO). We believe that enterprise logistics can no longer afford to optimize for just capital cost, or just delivery speed, or just carbon output. You must optimize for all of them simultaneously, finding the absolute mathematical Pareto-optimal path. However, multi-objective optimization is mathematically impossible if the specific variables you are trying to balance are trapped in disparate databases with entirely different refresh rates and data structures.
The traditional software industry has attempted to solve this by building application programming interfaces (APIs) and executive dashboards that simply pull numbers from these various silos and display them on a single unified screen. But a dashboard is just a reporting tool; it is not an engineering engine. It still relies on slow, batch-processed, CPU-bound architecture that looks backward at what has already happened, rather than calculating the physics and logistics of what needs to happen next.
To overcome this, we had to fundamentally rethink enterprise data architecture from the ground up. GreenSphere is designed to act as a unified, physics-based computational engine. Rather than just pulling numbers for a static dashboard, our architecture ingests these disparate data streams—physical material stress thresholds, real-time global meteorological feeds, and live ERP logistical constraints—and translates them into a single, cohesive digital environment. We move this unified dataset directly into our GPU Inference Core. By utilizing massively parallel computing, we completely break down the digital walls between procurement, logistics, and sustainability tracking.
Once the data is unified within this high-performance environment, the true power of our architecture is unlocked through Agentic AI. Because our agentic workflows have real-time, unrestricted access to the entire unified data sphere, they can autonomously negotiate across these previously siloed domains. If a storm threatens a maritime shipping lane, the Agentic AI doesn't just flash a warning light for the logistics team. It instantly cross-references the delay with the procurement budget, evaluates the physical structural requirements of the destination project, calculates the carbon penalty of terrestrial rerouting, and executes a holistic correction that keeps the entire enterprise on track.
The GreenSphere Vision
The transition to a low-carbon global economy requires more than just ambitious corporate pledges and shiny ESG reports; it requires a radical restructuring of how we manage operational data. We can no longer afford to let critical environmental and logistical data sit isolated in legacy servers. At GreenSphere Innovations, we are tearing down these silos by providing a unified, GPU-accelerated engine that sees the supply chain not as a series of disconnected departments, but as a single, living, multi-objective organism. By bringing absolute visibility and unprecedented computational power to enterprise logistics, we are giving organizations the exact tools they need to finally build a resilient, sustainable future.